데이터를 찾는 두가지 방법
Full Scan : 말 그대로 테이블 전체를 스캔한다.
Index Scan : 인덱스를 이용해서 스캔
Index Scan의 특징 : 정렬 / 위치
인덱스는 보통 큰 테이블에서 소량 데이터를 검색할 때 사용한다. 인덱스 튜닝이 중요한데
핵심요소는 두 가지이다.
1. 인덱스 스캔 과정에서 발생하는 비효율을 줄이는 것. => 인덱스 스캔 효율화 튜닝
2. 테이블 액세스 횟수를 줄이는 것 => 랜덤 액세스 최소화 튜닝
인덱스 스캔 효율화 튜닝과 랜덤 액세스 최소화 튜닝 둘 다 중요하지만, 더 중요한 하나를 고른다면
랜덤 액세스 최소화 튜닝. 이유는 성능에 미치는 영향이 더 크기 때문이다.
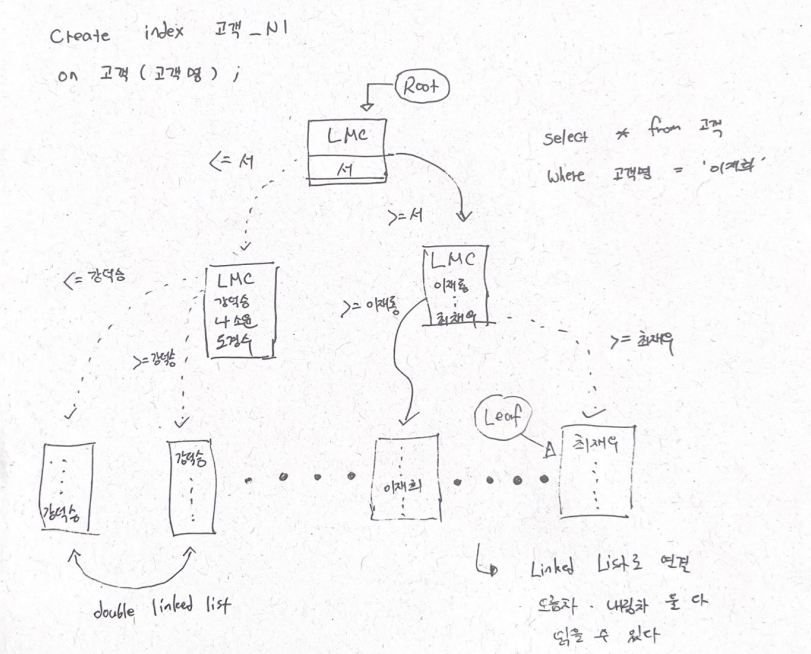
인덱스 탐색과정
수직적 탐색 / 수평적 탐색
수직적 탐색 : 인덱스 스캔 시작지점을 찾는 과정.
수평적 탐색 : 인덱스에서 본격적으로 데이터를 찾는 과정
제목 : 결합인덱스 생성 시 컬럼 배치 순서
select 이름, 성별
from 사원
where 성별 = '여자'
and 이름 = 유관순'
1. 인덱스를 성별 + 이름 순으로 구성한 경우
= > 총 사원 50명 중에서 성별 = '여자'인 레코드 25건을 찾고, 거기서 이름을 검사해 최종적으로 2명 출력 -> 2번의 검사
2. 인덱스를 이름 + 성별 순으로 구성한 경우
총 사원 50명 중에서 이름 = '유관순'인 레코드를 2건을 찾고, 거기서 성별을 검사해 최종적으로 2명 출력 -> 2번의 검사
선택도가 낮은 '이름' 컬럼을 앞에 두고 결합인덱스를 생성해야 검사 횟수를 줄일 수 있어서 성능에 유리한 것을 알 수 있다.
사실 두 조건이 True여야하기 때문에 순서가 중요하진 않다.
B*Tree 인덱스 ( Balanced Star Tree )
B*Tree 인덱스의 B가 Balanced의 약자이다.
가장 긴 트리와 짧은 트리의 길이가 1차이여야한다.
인덱스 기본 사용법
인덱스 기본 사용법은 인덱스를 Range Scan 하는 방법을 의미한다.
인덱스를 Range Scan 할 수 없는 이유
"인덱스 컬럼을 가공하면 인덱스를 정상적으로 사용 할 수 없다."
그 이유는 인덱스 스캔 시작점을 찾을 수 없기 때문이다.
인덱스를 쓸 수 없는 경우 정리
1. 컬럼변형
2. SubString
3. LIKE
4. OR
5. IN
IN이나 OR 같은 경우는 UNION ALL 방식으로 작성하면 사용이 가능하다
인덱스 사용 조건
인덱스를 Range Scan 하기 위한 가장 첫 번째 조건은 인덱스 선두 컬럼이 조건절에 있어야 한다. 가공되지 않은 상태로.
반대로 말하면, 인덱스 선두 컬럼이 가공되지 않은 상태로 조건절에 있으면 인덱스 Range Scan은 무조건 가능하다.
인덱스를 이용한 소트 연산 생략
인덱스를 Range Scan 할 수 있는 이유 및 테이블과 달리 인덱스를 사용하는 이유는 데이터가 정렬되어 있기 때문.
정렬되어 있기 때문에 Range Scan이 가능하고 소트 연산 생략 효과도 부수적으로 얻게된다.
SELECT *
FROM 상태변경이력
WHERE 장비번호 = 'C'
AND 변경일자 = '20180316'
Executin Plan
------------------------------------------
0 SELECT STATEMENT Optimizer = ALL_ROWS(Cost=85 Card=81 Bytes=5K)
1 0 TABLE ACCESS ( BY INDEX ROWID ) OF '상태변경이력' (TABLE)(Cost=85)
2 1 INDEX ( RANGE SCAN ) OF '상태변경이력_PK' (INDEX (UNIQUE)) (Cost=3)장비번호와 변경일자를 모두 '=' 조건으로 검색할 때 PK 인덱스를 사용하면 결과집합은
변경순번 순으로 출력된다
옵티마이저는 이런 속성을 활용해 아래와 같이 SQL에 ORDER BY가 있어도 정렬 연산을 따로 수행하지 않는다
PK 인덱스를 스캔하면서 출력한 결과집합은 어차피 변경순번순으로 정렬되기 때문.
SELECT *
FROM 상태변경이력
WHERE 장비번호 = 'C'
AND 변경일자 = '20180316'
ORDER BY 변경순번
Executin Plan
------------------------------------------
0 SELECT STATEMENT Optimizer = ALL_ROWS(Cost=85 Card=81 Bytes=5K)
1 0 TABLE ACCESS ( BY INDEX ROWID ) OF '상태변경이력' (TABLE)(Cost=85)
2 1 INDEX ( RANGE SCAN ) OF '상태변경이력_PK' (INDEX (UNIQUE)) (Cost=3)인덱스를 이용해서 SORT 처리를 했기 때문에 SORT가 없음
ORDER BY 절에서 컬럼 가공
SELECT *
FROM 상태변경이력
WHERE 장비번호 = 'C'
ORDER BY 변경일자, 변경순번SQL 정렬 연산을 생략할 수 있는 이유 :
수직적 탐색을 통해 장비번호가 'C'인 첫 번째 레코드를 찾아 인덱스 리프 블록을 스캔하면,
자동으로 변경일자 + 변경순번 순으로 정렬되기 때문
SELECT *
FROM 상태변경이력
WHERE 장비번호 = 'C'
ORDER BY 변경일자 || 변경순번위처럼 작성하면 정렬 연산을 생략할 수 없다.
인덱스에는 가공하지 않은 상태로 값을 저장했는데, 가공한 값 기준으로 정렬해 달라고 요청했기 때문.
SELECT - LIST에서 컬럼 가공
인덱스를 장비번호 + 변경일자 + 변경순번 순으로 구성하면 변경순번 최소값을 구할 때도 옵티마이저는 정렬 연산을
따로 수행하지 않아도 된다.
수직적 탐색을 통해 조건을 만족하는 가장 왼쪽 지점으로 내려가서 첫 번째 읽는 레코드가 바로 최소값이기 때문
최대값 또한 마찬가지이다.
최대값을 찾을 때는 오른쪽으로 내려가는 점만 최소값과 다르다.
SELECT NVL(MAX(TO_NUMBER(변경순번)),0)
FROM 상태변경이력
WHERE 장비번호 = 'C'
AND 변경일자 = '20180316'
Rows Row Source Operation
---- ---------------------
0 STATEMENT
1 SORT AGGREGATE (cr=1670 pw=0 time=101326 us)
131577 INDEX RANGE SCAN 상태변경이력_PK (cr=1670 pr=0 pw=0)아래와 같이 바꾸면 정렬 연산 없이 최종 변경 순번을 쉽게 찾을 수 있다.
SELECT NVL(TO_NUMBER(MAX(변경순번)),0)
FROM 상태변경이력
WHERE 장비번호 = 'C'
AND 변경일자 = '20180316'
Rows Row Source Operation
---- ---------------------
0 STATEMENT
1 SORT AGGREGATE (cr=4 pw=0 time=81 us)
1 FIRST ROW(cr=4 pr=0 pw=0 time=59 us)
1 INDEX RANGE SCAN (MIN/MAX) 상태변경이력_PK (cr=4 pr=0 pw=0)
자동 형변환
SQL 성능 원리를 잘 모르는 개발자는 TO_CHAR, TO_DATE, TO_NUMBER 같은 형변환 함수를 의도적으로 생략한다.
함수를 생략하면 연산횟수가 줄어 성능이 더 좋지 않을까라고 생각하기 때문.
하지만 성능은 그런 데서 결정되는 것이 아니라 블록 I/O를 줄일 수 있느냐 없느냐에서 결정된다.
형변환 함수를 생략한다고 연산 횟수가 주는 것이 아닌 옵티마이저가 자동으로 생성한다.
인덱스 확장 기능 사용법

Index Range Scan :
수직 : 시작점을 찾는 것 / 수평탐색을 얼마나 줄이냐가 핵심
인덱스를 Range 하기 위해선 선두 컬럼을 가공하지 않은 상태로 조건절에 사용해야한다.
반대로 선두 컬럼을 가공하지 않은 상태로 조건절에 사용하면 Index Range Scan은 무조건 가능하다.

Index Full Scan :
수직탐색이 없음
Index Full Scan은 대게 데이터 검색을 위한 최적의 인덱스가 없을 때 차선으로 선택

Index Unique Scan :
수직적 탐색만으로 데이터를 찾는 스캔 방식
Unique 인덱스를 '=' 조건으로 탐색하는 경우에 작동
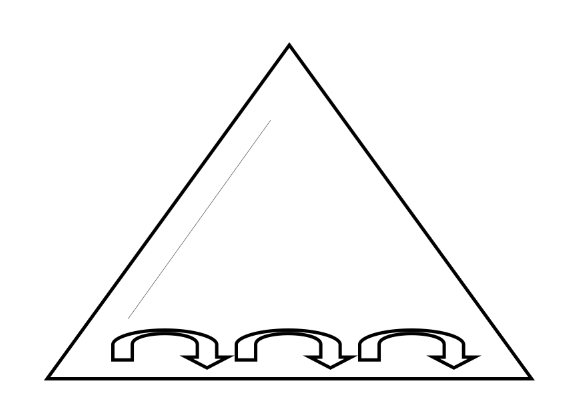
Index Skip Scan :
수평스캔을 건너뛸때
똑같은 데이터가 계속 나오면 스킵한다.
Distinct Value가 많이 없을때 ( 남 or 여 ) 사용 가능하다.
사용할 수 있는 조건이 까다롭다.

링크드리스트는 순차적이지만 위치는 순차적이지 않다. 인덱스 풀스캔은 테이블 스캔보다 느림.
Index Full Scan :
정렬을 신경쓰지 않고 갖고온다
Multiblock I/O 방식을 사용.
속도는 빠르지만, 인덱스 리프 노드가 갖는 연결 리스트 구조를 무시한 채 데이터를 읽기 때문에 결과집합이
인덱스 키 순서대로 정렬되지 않음.
Index Full Scan과 Index Fast Full Scan 특징 요약
| Index Full Scan | Index Fast Full Scan |
| 1. 인덱스 구조를 따라 스캔 2. 결과집합 순서 보장 3. Single Block I/O 4. (파티션 돼 있지 않다면) 병렬스캔 불가 5. 인덱스에 포함되지 않은 컬럼 조회 시에도 사용 가능 |
1. 세그먼트 전체를 스캔 2. 결과집합 순서 보장 X 3. Multiblock I/O 4. 병렬스캔 가능 5. 인덱스에 포함된 컬럼으로만 조회할 때 사용 가능 |

Index Range Scan Descending :
Index Range Scan과 기본적으로 동일한 스캔방식이지만 뒤에서부터 앞쪽으로 스캔한다
'SQL > 심화' 카테고리의 다른 글
| SQL튜닝 - Chapter04.조인튜닝 -2- 소트 머지 조인 (0) | 2023.08.21 |
|---|---|
| SQL튜닝 - Chapter04.조인튜닝 -1- NL조인 (0) | 2023.08.19 |
| SQL튜닝 - Chapter03. 인덱스튜닝 -2- (0) | 2023.08.18 |
| SQL튜닝 - Chapter03. 인덱스튜닝 -1- (2) | 2023.08.18 |
| SQL튜닝 - Chapter01. SQL처리과정과 I/O (1) | 2023.08.16 |



