인덱스를 스캔하는 이유
- 검색조건을 만족하는 소량의 데이터를 인덱스에서 빨리 찾고 테이블레코드를 찾아가기 위한 주소값 = ROWID를 얻기위해
인덱스 ROWID는 논리적주소
- 디스크 상에서 테이블 레코드를 찾아가기 위한 위치 정보를 담는다

인덱스를 이용해 테이블 블록을 찾아가는 과정
인덱스 클러스터링 팩터 ( Index Clustering Factor )
클러스터링 팩터(Clustering Factor) : 특정 컬럼을 기준으로 같은 값을 갖는 데이터가 서로 모여있는 정도
클러스터링 팩터가 좋은 컬럼에 생성한 인덱스는 검색 효율이 매우 좋다
= 테이블 액세스량에 비해 블록I/O가 적게 발생함을 의미하는 것
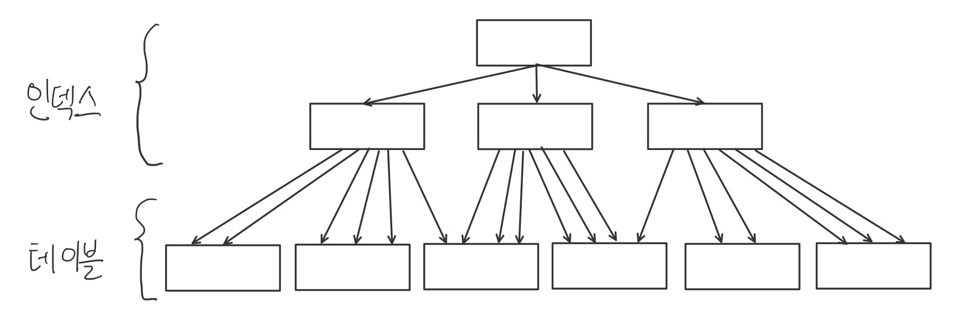
- 인덱스 클러스터링 팩터가 가장 좋은 상태를 도식화한 것-
인덱스 레코드 정렬 순서와 테이블 레코드 정렬순서가 100% 일치
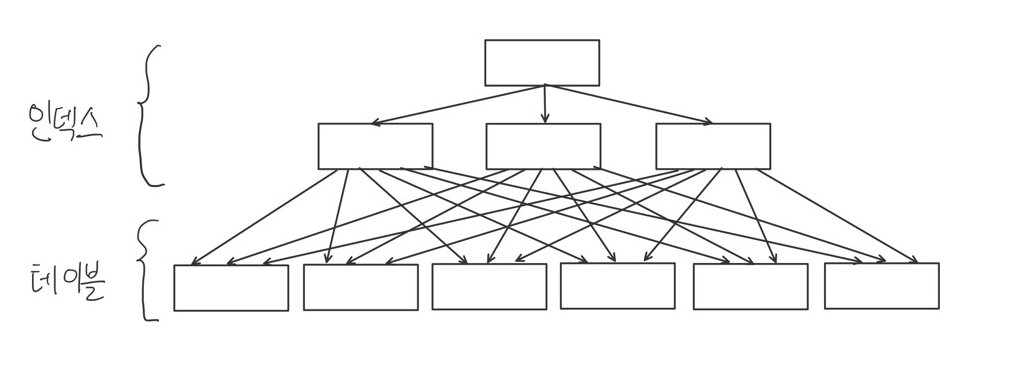
- 인덱스 클러스터링 팩터가 가장 안좋은 상태를 도식화한 것-
인덱스 레코드 정렬 순서와 테이블 레코드 정렬 순서가 전혀 일치하지 않음
인덱스 손익분기점
Index Range Scan에 의한 테이블 액세스가 Table Full Scan보다 느려지는 지점을 인덱스 손익분기점

인덱스를 이용해 테이블을 액세스할 때는 몇 건을 추출하느냐에 따라 성능이 크게 달라진다.
다시말해, 추출 건수가 많을 수록 느려진다
인덱스를 이용한 테이블 액세스가 Table Full Scan보다 더 느려지게 만드는 가장 핵심적인 요인 2가지
1. Table Full Scan은 시퀀스 액세스이지만, 인덱스 ROWID를 이용한 테이블 액세스는 랜덤 액세스 방식
2. Table Full Scan은 Multiblock I/O이지만, 인덱스 ROWID를 이용한 테이블 액세스는 Single Block I/O
인덱스 손익분기점은 보통 5 ~ 20%의 낮은 수준에서 결정된다
클러스터링 팩터가 나쁘면 손익분기점은 5%미만, 아주 좋을때는 90% 수준까지도 올라가기도 한다
(밑 그림을 참고하면 좋다)

손익분기점이란 개념을 사용했을때 테이블 스캔이 항상 나쁜 것은 아니며, 바꿔 말해 인덱스 스캔이 항상 좋은 것도 아니라는 사실이다.
온라인 트랜잭션(OLTP)을 처리하는 프로그램과 DW/OLAP/배치 프로그램 튜닝의 특징을 구분 짓는 핵심 개념
DW : 데이터 웨어하우스.
사용자의 의사 결정에 도움을 주기 위하여 기간시스템의 데이터베이스에 축적된 데이터를 공통의 형식으로 변환해서 관리하는 데이터베이스
OALP : 데이터 웨어하우스
데이터 마트 또는 기타 중앙화된 통합 데이터 저장소의 대용량 데이터를 고속으로 다차원 분석하는 소프트웨어
배치 프로그램 : 대량 데이터를 읽고 가공해서 다른 테이블에 입력, 대량 데이터를 읽괄 수정/삭제하는 프로그램
온라인 프로그램 튜닝 VS 배치 프로그램 튜닝
(온라인 프로그램은 소량 데이터를 읽고 갱신 , 배치 프로그램은 데이터를 쌓아놨다가 처리
= 데이터 성격에 따라 튜닝하는 방식이 달라진다 )
온라인 프로그램은 소량 데이터를 읽고 갱신하기 때문에 인덱스를 효과적으로 활용하는 것이 중요하다.
조인도 대부분 NL조인을 사용.
배치 프로그램은 대량 데이터를 읽고 갱신하기 때문에 항상 전체범위 처리 기준으로 튜닝해야 한다.
처리대상 집합 중 일부분을 빠르게 처리하는 것이 아닌 전체를 빠르게 처리하는 것이 목적.
대량 데이터를 빠르게 처리하려면 인덱스와 NL조인을 사용하는 것보다 Full Scan 방식과 해시 조인이 유리
하지만, 초대용량 테이블을 Full Scan 하면 오래 기다려야 하고, 시스템에 부담도 주기 때문에
배치 프로그램에서 파티션 활용 전략이 매우 중요한 튜닝 요소이다.
테이블을 파티셔닝하는 이유는 결국엔 Full Scan을 빠르게 하기 위해서이다.
= ( 인덱스 성능을 높이는 것이 아닌 Full Scan 성능을 올리는 것 )
인덱스 컬럼 추가
테이블 액세스 최소화를 위해 가장 일반적으로 사용하는 튜닝 기법은 인덱스에 컬럼을 추가하는 것
 -1- |
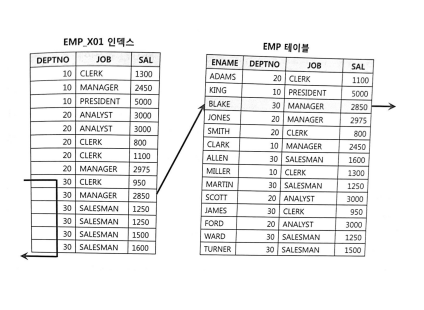 -2- |
1번 그림은 한 명을 찾기 위해 테이블을 6번 액세스한 것이고
2번 그림은 기존 인덱스에 SAL 컬럼을 추가해서 인덱스 스캔량은 줄지 않았지만 테이블 랜덤 액세스 횟수를 줄여준다
인덱스 구조 테이블 ( IOT : Index-Organized Table )
오라클에서 랜덤 액세스가 아예 발생하지 않도록 테이블을 인덱스 구조로 생성하는 것

인덱스 클러스터 테이블

클러스터 키 값이 같은 레코드를 한 블록에 모아서 저장하는 구조.
만약 한 블록에 모두 담을 수 없을 때는 새로운 블록을 할당해서 클러스터 체인으로 연결한다.
해시 클러스터 테이블
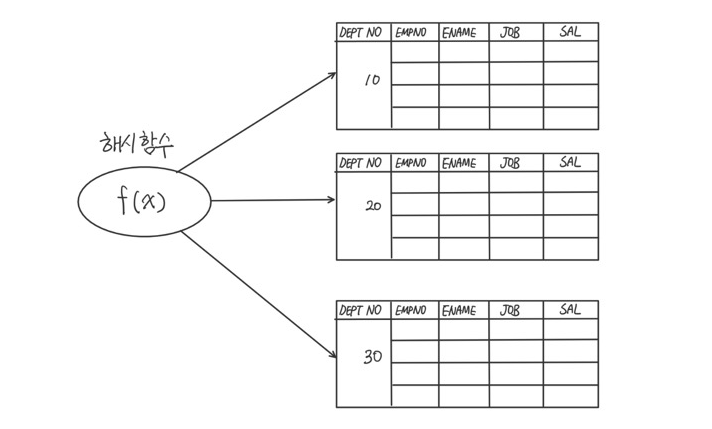
인덱스를 사용하지 않고 해시 알고리즘을 사용해 클러스터를 찾아간다는 점이 다르다.
부분범위 처리 활용
전체 쿼리 결과집합을 쉼 없이 연속적으로 전송하지 않고 사용자로부터 Fetch Call이 있을때 마다
일정량씩 나누어 전송하는 것
쉽게 생각하면 처음부터 다 나오는 것이 아닌 스크롤 내리면 다음 데이터가 나오는 것.

예를 들어 1억 건짜리 테이블인데도 결과를 빨리 출력할 수 있는 이유는 부분 범위 처리하기 때문이다.
-2편에서 계속-
'SQL > 심화' 카테고리의 다른 글
| SQL튜닝 - Chapter04.조인튜닝 -2- 소트 머지 조인 (0) | 2023.08.21 |
|---|---|
| SQL튜닝 - Chapter04.조인튜닝 -1- NL조인 (0) | 2023.08.19 |
| SQL튜닝 - Chapter03. 인덱스튜닝 -2- (0) | 2023.08.18 |
| SQL튜닝 - Chapter02. 인덱스기본 (0) | 2023.08.17 |
| SQL튜닝 - Chapter01. SQL처리과정과 I/O (1) | 2023.08.16 |



