소트 수행 과정
소트는 기본적으로 PGA에 할당한 Sort Area에서 이루어진다 . Sort Area가 다 차면 디스크 Temp 테이블 스페이스를 활용한다.
Sort Area에서 작업을 완료할 수 있는지에 따라 소트를 두 가지 유형으로 나뉨
- 메모리 소트(In - Memory Sort ) : 전체 데이터의 정렬 작업을 메모리 내에서 완료하는 것을 말하며, 'Internal Sort' 라고도 한다.
- 디스크 소트(To - Disk Sort ) : 할당받은 Sort Area 내에서 정렬을 완료하지 못해 디스크 공간까지 사용하는 경우를 말하며, 'External Sort' 라고도 한다.
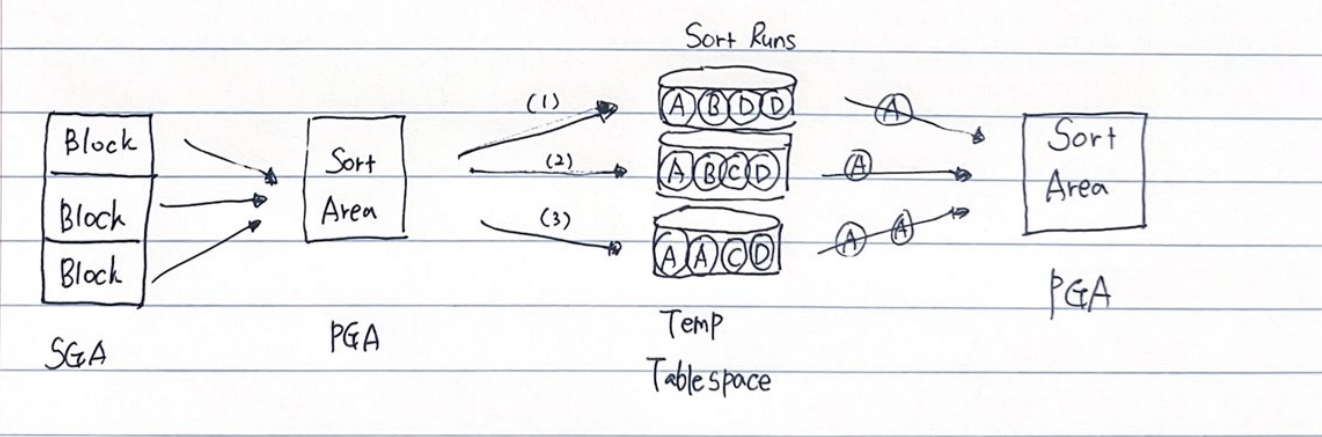
소트 연산은 메모리 집약적 ( Memory - intensive ) 일 뿐만 아니라 CPU 집약적 ( CPU - intensive )이기도 하다.
[ 메모리를 많이 사용하고 , CPU를 많이 사용한다 ]
데이터량이 많을 때는 디스크 I/O까지 발생하므로 쿼리 성능을 좌우하는 매우 중요한 요소.
많은 서버 리소스를 사용하고 디스크 I/O가 발생하는 것도 문제지만, 부분범위 처리를 불가능하게 함으로써 OLTP 환경에서 애플리케이션 성능을 저하시키는 주요인.
Sort Aggregate
SQL > select sum(sal), max(sal), min(sal), avg(sal) from emp;
-------------------------------------------------------------
ID Operation Name Rows Bytes Cost (%CPU) Time
-------------------------------------------------------------------------
0 SELECT STATEMENT 1 4 3 ( 0 ) 00:00:01
1 SORT AGGREGATE 1 4
2 TABLE ACCESS FULL EMP 14 56 3 ( 0 ) 00:00:01Sort Aggregate는 아래 전체 로우를 대상으로 집계를 수행할 때 나타난다.
'Sort'라는 표현을 사용하지만, 실제로 데이터를 정렬하지 않는다
데이터를 정렬하지 않고 SUM, MAX, MIN, AVG 값 구하는 절차는 다음과 같다

Sort Area에 SUM, MAX, MIN, COUNT 값을 위한 변수를 하나씩 할당
EMP 테이블 첫 번째 레코드에서 읽은 SAL 값을 SUM, MAX, MIN 변수에 저장, COUNT 변수 1을 저장한다

EMP 테이블 레코드를 하나씩 읽어 내려가면서 SUM 변수에는 값을 누적 / MAX 변수에는 기존보다 큰 값이 나타날때 마다 값 대체 / MIN 변수에는 기존보다 작은 값 나타날때 마다 값 대체 / COUNT 변수에는 SAL 값이 NULL이 아닌 레코드 만날 때마다 1씩 증가
레코드를 다 읽고나면 SUM, MAX, MIN값은 변수에 담긴 값을 그대로 출력, AVG는 SUM 값을 COUNT값으로 나눠서 출력하면 된다.
소트가 발생하지 않도록 SQL 작성
SQL 작성할 때 불필요한 소트가 발생하지 않도록 주의해야 한다.
성능이 느리다면 소트 연산을 피할 방법이 있는지 찾아봐야 한다. [ Union, Minus, Distinct 연산자는 소트 연산 발생시킴.]
Union vs. Union All
SQL에 Union을 사용하면 옵티마이저는 상단과 하단 두 집합 간 중복을 제거하려고 작업을 수행.
반면에 Union All은 중복을 확인하지 않고, 두 집합을 단순히 결합하므로 소트 작업을 수행하지 않는다. 그렇기 때문에 될 수 있으면 Union All을 사용해야 한다.
select 결제번호/ 주문번호/ 결제금액/ 주문일자 ·
from 결제
where 결제수단코드 = 'M' and 결제일자 = '20180316 ’
UNION
select 결제번호/ 주문번호/ 결제금액/ 주문일자 ..
from 결제
where 결제수단코드 = 'C ’ and 결제일자 = '20180316 ’
Execution Plan
----------------------------------------------------------------
o SELECT STATEMENT Optimizer=ALL_ROWS (Cost=4 Card=2 Bytes=106)
1 0 SORT (UNIQUE) (Cost=4 Card=2 Bytes=106)
2 1 UNION-ALL
3 2 FILTER
4 3 TABLE ACCESS (BY INDEX ROWID) OF ’ 결제 , (TABLE) (Cost=1 ... )
5 4 INDEX (RANGE SCAN) OF ' 결저I N1 ’ (INDEX) (Cost=1 Card=1)
6 2 FILTER
7 6 TABLE ACCESS (BY INDEX ROWID) OF ‘ 결제 , (TABLE) (Cost=1 ... )
8 7 INDEX (RANGE SCAN) OF ' 결저I_N1 ’ (INDEX) (Cost=1 Card=1)Union 상단과 하단 집합 사이에 인스턴스 중복 가능성이 없다. 결제수단코드 조건절에 다른 값을 입력했기 때문.
그치만 Union을 사용함으로써 소트 연산을 발생시키고 있다
= Union All을 사용해야 한다.
select 결제번호/ 결제수단코드/ 주문번호1 결제금액/ 결제일자, 주문일자 ·
from 결제
where 결제일자 = ’20180316'
UNION
select 결제번호/ 결제수단쿄드/ 주문번호/ 결제금액/ 결제일자/ 주문일자 ..
from 결제
where 주문일자 = '20180316'
Execution Plan
----------------------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=2 Card=2 Bytes=106)
1 o SORT (UNIQUE) (Cost=2 Card=2 Bytes=106)
2 1 UNION-ALL
3 2 FILTER
4 3 TABLE ACCESS (BY INDEX ROWID) OF ’ 결제 ’ (TABLE) (Cost=0 ... )
5 4 INDEX (RANGE SCAN) OF ’ 결저I N2 ‘ (INDEX) (Cost=0 Card=1)
6 2 FILTER
7 6 TABLE ACCESS (BY INDEX ROWID) OF ' 결제 ’ (TABLE) (Cost=0
8 7 INDEX (RANGE SCAN) OF ' 결저I_N3' (INDEX) (Cost=0 Card=1)Union 상단과 하단 집합 사이에 인스턴스 중복 가능성이 있다
= Union을 사용해야 한다
소트 연산이 일어나지 않도록 Union All을 사용하면서도 데이터 중복을 피하려면, 이렇게 해야한다.
select 결제번호/ 결제수단코드/ 주문번호/ 결제금액/ 결제일자/ 주문일자 ...
from 결제
where 결제일자 = ’ 20180316'
UNION ALL
select 결제번호 / 결제수단코드/ 주문번호/ 결제금액/ 결제일자/ 주문일자 ·
from 결제
where 주문일자 = '20180316'
and 결제일자 <> ’ 20180316'
Execution Plan
-----------------------------------------------------------------------
o SELECT STATEMENT Optimizer=ALL_ROWS (Cost=0 Card=2 Bytes=106)
1 0 UNION-ALL
2 1 FILTER
3 2 TABLE ACCESS (BY INDEX ROWID) OF ’ 결저| ’ (TABLE) (Cost=0 Card=1 ... )
4 3 INDEX (RANGE SCAN) OF ’ 결저 N2' (INDEX) (Cost=0 Card=1)
5 1 FILTER
6 5 TABLE ACCESS (BY INDEX ROWID) OF ’ 결제 , (T ABLE) (Cost=0 Card=1 .. . )
7 6 INDEX (RANGE SCAN) OF ’ 결저I_N3 ’ (INDEX) (Cost=0 Card=1)결제일자가 Null 허용 컬럼이면 맨 아래 조건절을 이렇게 변경해야 한다.
and ( 결제일자 <> '20180316' or 결제일자 is null )
이렇게 LNNVL 함수를 이용해도 된다
and LNNVL(결제일자 = '20180316' )
Exists 활용
중복 레코드를 제거할 목적으로 Distinct 연산자를 종종 사용.
[Distinct도 정렬을 사용한다.]
Distinct를 사용하면 조건에 해당하는 데이터를 모두 읽어서 중복을 제거해야 한다. 많은 I/O가 발생.
Exists 서브쿼리는 데이터 존재 여부만 확인하면 되기 때문에 조건절을 만족하는 데이터를 모두 읽지 않는다.
Distinct, Minus 연산자를 사용한 쿼리는 대부분 Existst 서브쿼리로 변환 가능하다.
Top N 쿼리
( Ex. Top10 , Top3, Top5 )
Top N 쿼리는 전체 결과집합 중 상위 N개 레코드만 선택하는 쿼리.
반복문을 1번만 돌리고, 정렬은 안하기 때문에 빠르다.
Sort Area를 적게 사용하도록 SQL 작성
- PGA 범위안에서 사용하기 위해서. [ 디스크로 넘어가면 느려진다 ]
소트 연산이 불가피하다면 메모리 내에서 처리를 완료할 수 있도록 노력해야 한다.
Sort Area를 적게 사용할 방법부터 찾아야 한다.
SELECT *
FROM 예수금원장
ORDER BY 총예수금 desc
Excution Plan
----------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=184K Card=2M Bytes=716M)
1 0 SORT (ORDER BY) (Cost=184K Card=2M Bytes=716M)
2 1 TABLE ACCESS (FULL) OF '예수금원장' (TABLE) (Cost=25K Card=2M Bytes=716M)
SELECT 계좌번호, 총예수금
FROM 예수금원장
ORDER BY 총예수금 desc
Excution Plan
----------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=31K Card=2M Bytes=17M)
1 0 SORT (ORDER BY) (Cost=31K Card=2M Bytes=17M)
2 1 TABLE ACCESS (FULL) OF '예수금원장' (TABLE) (Cost=24K Card=2M Bytes=17M)위 SQL 문장과 아래 SQL 문장 중에서
아래 SQL 문장이 Sort Area를 적게 사용한다. 그 이유는
위 SQL은 모든컬럼을 Sort Area에 저장하는 반면, 아래 SQL은 계좌번호와 총예수금만 저장하기 때문.
'SQL > 심화' 카테고리의 다른 글
| SQL튜닝 - Chpater07. SQL옵티마이저 (0) | 2023.08.26 |
|---|---|
| SQL튜닝 - Chapter06.DML 튜닝 (0) | 2023.08.23 |
| SQL튜닝 -Chapter04.조인튜닝 -4- 서브퀴리 조인 (0) | 2023.08.22 |
| SQL튜닝 -Chapter04.조인튜닝 -3- 해시 조인 (1) | 2023.08.21 |
| SQL튜닝 - Chapter04.조인튜닝 -2- 소트 머지 조인 (0) | 2023.08.21 |


