DML 성능에 영향을미치는 요소
( DML : Insert + Delete + Update )
- 인덱스
- 무결성 제약
- 조건절
- 서브쿼리
- Redo 로깅
- Undo 로깅
- Lock
- 커밋
테이블에 레코드를 입력하면, 인덱스에도 입력. 테이블은 Freelist를 통해 입력
Freelist : 테이블마다 데이터 입력이 가능한(여유 공간이 있는) 블록 목록을 관리
인덱스 개수가 DML 성능에 미치는 영향이 매우 큰 만큼, 인덱스 설계에 심혈을 기울여야 한다.
핵심 트랜잭션 테이블에서 인덱스 하나라도 줄이면 TPS(Transcation Per Second)는 그만큼 향상된다.
무결성 제약과 DML 성능
데이터베이스에 논리적으로 의미 있는 자료만 저장되게 하는 데이터 무결성 규칙으로는 네 가지가 있다
- 개체 무결성 ( Entity Integrity )
- 참조 무결성 ( Referential Integrity )
- 도메인 무결성 ( Domain Integrity )
- 사용자 정의 무결성 ( 또는 업무 제약 조건 )
DBMS에서 PK, FK, Check, Not Null 같은 제약을 설정하면 더 완벽하게 데이터 무결성을 지켜낼 수 있다
PK, FK 제약은 Check, Not Null 제약보다 성능에 더 큰 영향을 미친다.
Redo 로깅과 DML 성능
오라클은 모든 변경사항을 Redo 로그에 기록한다.
DML을 수행할 때마다 Redo 로그를 생성해야 하므로 Redo 로깅은 DML 성능에 영향을 미친다. INSERT 작업에 대해
Redo 로깅 생략 기능을 제공하는 이유가 여기에 있다
Redo 로그의 용도
1. Redo 로그는 물리적으로 디스크가 깨지는 등의 Media Fail 발생 시 데이터베이스를 복구하기 위해 사용.
2. Redo 로그는 'Cache Recovery'를 위해 사용하며 다른 말로 'Instance Recovery'라고도 한다.
3. Redo 로그는 'Fast Commit'을 위해 사용. 메모리 버퍼블록을 디스크 상의 데이터 블록에 반영하는 작업은
랜덤 액세스 방식으로 이루어지므로 매우 느리다. 로그는 Append 방식으로 기록하므로 상대적으로 빠르다
트랜잭션에 의한 변경사항을 우선 Append 방식으로 빠르게 로그 파일에 기록하고, 변경된 메모리 버퍼블록과
데이터파일 블록 간 동기화는 적절한 수단(DBWR, Checkpoint)을 이용해 나중에 배치(Batch) 방식으로 일괄 수행
사용자의 갱신내용이 메모리상의 버퍼블록에만 기록된 채 아직 디스크에 기록되지 않았지만 Redo 로그를 믿고
빠르게 커밋을 완벽한다는 의미에서 이를 'Fast Commit'이라고 부른다.
Undo의 용도와 MVCC 모델
오라클은 데이터를 입력, 수정, 삭제할 때마다 Undo 세그먼트에 기록을 남긴다. Undo 데이터를 기록하 공간은
해당 트랜잭션이 커밋하는 순간, 다른 트랜잭션이 재사용할 수 있는 상태로 바뀐다.
가장 오래 전에 커밋한 Undo 공간부터 재사용하므로 Undo 데이터가 곧바로 사리지진 않겠지만, 언젠가
다른 트랜잭션 데이터로 덮어쓰이면서 사라질 수 밖에 없다.
Lock과 DML 성능
Lock은 DML 성능에 매우 크고 직접적인 영향을 미친다. Lock을 필요 이상으로 자주, 길게 사용하거나 레벨을 높일수록
DML 성능은 느려진다.
Lock을 너무 적게, 짧게 사용하거나 필요한 레벨 이하로 낮추면 데이터 품질이 나빠진다. = 적정점을 찾아야 한다.
트랜잭션 데이터 저장 과정

테이블파티션
파티셔닝(Partitioning)은 테이블 또는 인덱스 데이터를 특정 컬럼(파티션 키) 값에 따라 별도 세그먼트에 나눠서
저장하는 것
- 관리적 측면 : 파티션 단위 백업, 추가, 삭제, 변경 → 가용성 향상
- 성능적 측면 : 파티션 단위 조회 및 DML, 경합 또는 부하 분산
파티션에는 Range, 해시,리스트 세 종류
- Range 파티션 : 범위별로 파티션.
- 해시 파티션 : 나누는 기준이 없어서 입력받은 값 중 같은 값으로 나눈 것.
- 리스트 파티션 : 순서와 상관없이 불연속적인 값으로 나눈 것.
Lock과 트랜잭션 동시성 제어
오라클 Lock
오라클은 DML Lock, DDL Lock, 래치, 버퍼 Lock, 라이브러리 캐시 Lock/Pin 등 다양한 종류의 Lock을 사용
래치 : SGA에 공유된 각종 자료구조를 보호하기 위해 사용
버퍼 Lock : 버퍼 블록에 대한 액세스를 직렬화하기 위해 사용
라이브러리 캐시 Lock과 Pin은 라이브러리 캐시에 공유된 SQL 커서와 PL/SQL 프로그램을 보호하기 위해 사용
DML 로우 Lock
두 개의 동시 트랜잭션이 같은 로우를 변경하는 것을 방지.
DML 로우 Lock에는 배타적 모드를 사용하므로 UPDATE 또는 DELETE를 진행중인(아직 커밋하지 않은) 로우를 다른
트랜잭션이 UPDATE하거나 DELETE 할 수 없다.
INSERT에 대한 로우 Lock 경합은 Unique 인덱스가 있을 때만 발생.
두 트랜잭션이 서로 다른 값을 입력하거나 Unique 인덱스가 아예 없으면, INSERT에 대한 로우 Lock 경합은 발생하지 않음
오라클 SELECT 문에 로우 Lock을 사용하지 않는다. 오라클은 다른 트랜잭션이 변경한 로우를 읽을 때 복사본 블록을 만들어서 쿼리가 '시작된 시점'으로 되돌려서 읽는다. 변경이 진행중인 로우를 읽을 때도 Lock이 풀릴 때까지 기다리지 않고 복사본을 만들어서 읽는다. SELECT 문에 Lock을 사용할 필요가 없다.
오라클에서는 DML과 SELECT는 서로 진행을 방해하지 않는다. 물론 SELECT끼리도 서로 방해하지 않는다
MVCC 모델을 사용하지 않는 DBMS는 SELECT 문에 공유 Lock을 사용
DML 테이블 Lock
오라클은 DML 로우 Lock을 설정하기에 앞서 테이블 Lock을 먼저 설정.
| Null | RS | RX | S | SRX | X | |
| Null | O | O | O | O | O | O |
| RS | O | O | O | O | O | |
| RX | O | O | O | |||
| S | O | O | O | |||
| SRX | O | O | ||||
| X | O |
- RS : row shar ( 또는 SS : sub share) 한 줄 단위
- RX : row exclusive ( 또는 SX : sub exclusive ) 배타
- S : share ( 테이블 레벨. R이 안붙었기 때문 )
- SRX : share row exclusive ( 또는 SSX : share/sub exclusive )
- X : exclusive
테이블 Lock이라고 하면, 테이블 전체에 Lock이 걸린다고 생각하기 쉽다. 그래서 다른 트랜잭션이 더는 레코드를
추가하거나 갱신하지 못하게 막는 것이 아님
오라클에서 말하는 테이블 Lock은 어떤 작업을 수행 중인지를 알리는 일종의 푯말.
대상 리소스가 사용 중일 때, 진로 선택
Lock을 얻고자 하는 리소스가 사용 중일 때, 프로세스는 아래 세 가지 방법 중 하나를 택함
사용자가 이 세 가지 옵션을 모두 선택할 수 있는 문장이 SELECT FOR UPDATE문
1. Lock이 해제될 때까지 기다린다. (예 : select * from t for update)
2. 일정 시간만 기다리다 포기한다. (예 : select * from t for update wait 3)
3. 기다리지 않고 작업을 포기한다. (예 : select * from t for update nowait)
Lock을 풀 수 있는 방법 2가지
- 롤백
- 커밋
커밋 옵션 네 가지
- WAIT(Defualt) : LGWR가 로그버퍼를 파일에 기록했다는 완료 메시지를 받을 때 까지 기다린다(동기식 커밋)
- NOWAIT : LGWR의 완료 메시지를 기다리지 않고 바로 다음 트랜잭션을 진행한다 (비동기식 커밋)
- IMMEDIATE : 커밋 명령을 받을 때마다 LGWR가 로그 버퍼를 파일에 기록한다
- BATCH : 세션 내부에 트랜잭션 데이터를 일정량 버퍼링했다가 일괄 처리한다
트랜잭션 동시성 제어 두 가지
비관적 동시성 제어 : 사용자들이 같은 데이터를 동시에 수정할 것으로 가정 ( Lock을 확인 하고 작업)
낙관적 동시성 제어 : 사용자들이 같은 데이터를 동시에 수정하지 않을 것으로 가정 ( Lock을 확인 안하고 작업)
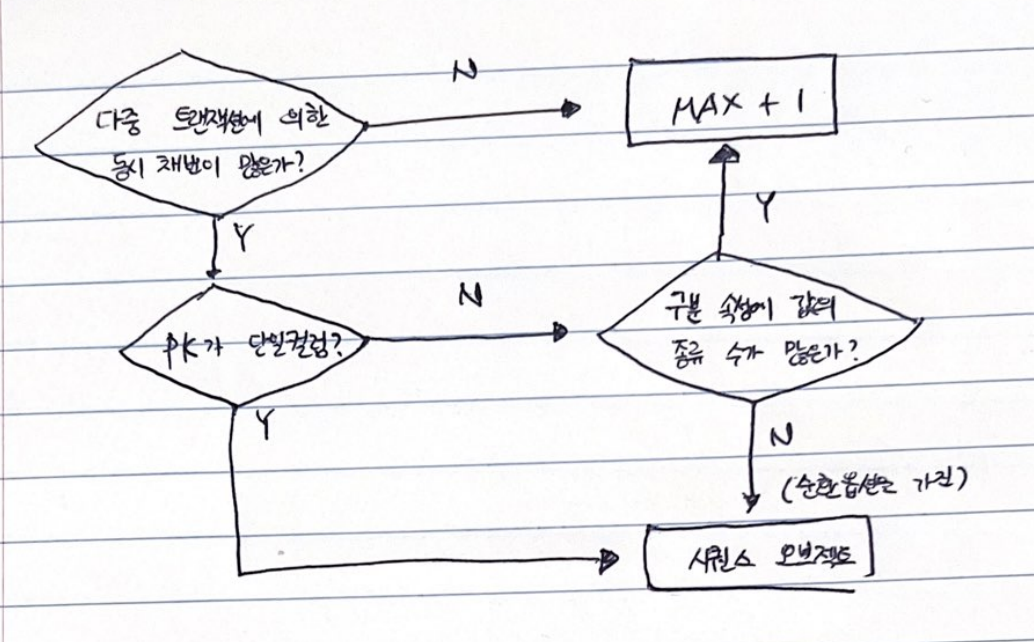
채번 방식에 따른 INSERT 성능 비교
INSERT, UPDATE, DELETE, MERGE 중 가장 중요하고 튜닝 요소가 많은 것은 INSERT. 그러나 채번 방식에 따른 성능 차이가 매우 크기 때문
채번 방식에는 세 가지가 있다
- 채번 테이블 (테이블 이용) [다른 채번 방식에 비해 성능이 안좋다]
= 각 테이블의 식별자의 단일컬럼 일련번호 또는 구분 속성별 순번을 채번하기 위해 별도 테이블을 관리하는 방식
- 시퀀스 오브젝트 (시퀀스 이용) [기본적으로 PK가 단일컬럼일 때만 사용가능]
= 시퀀스의 가장 큰 장점은 성능이 빠르다
- MAX +1 조회 ( 쿼리 한번 해줘야함) [레코드 중복에 대한 세밀한 예외처리가 필요 / 다중 트랜잭션에 의한 동시 채번이 심하면 시퀀스보다 성능이 많이 나빠질 수 있다]
= 대상 테이블의 최종 일련번호를 조회하고, 거기에 1을 더해서INSERT하는 방식
| 채번 방식 | 식별자 구조 | 주요 경합 | 부수적인 경합 | 비고 |
| 채번 테이블 | 일련번호 | (값 변경을 위한) 로우 Lock 경합 |
(동시성이 높다면) 채번 테이블 블록 경합 |
채번 테이블 관리 부담 |
| 구분+순번 | 단일 일련번호일 때보다 Lock 경합 감소 | |||
| 시퀀스 오브젝트 | 일련번호 | 시퀀스 경합 | (시퀀스 경합 해소 시) 인덱스 블록 경합 |
- 시퀀스 관리 부담 - INSERT 과정에 결번 가능성 |
| MAX + 1 | 일련번호 | (입력 값 중복 시) 로우 Lock+재실행 |
(동시성이 매우 높다면) 인덱스 블록 경합 |
-별도 오브젝트 관리 없음 - 중복 값 발생에 대비한 예외처리 필수 - PK 인덱스 구성에 따른 성능 차이 발생 |
| 구분+순번 | 단일 일련번호일 때보다 Lock 경합 감소 (구분 속성 값의 종류 수가 많으면, 현저히 감소) |
|||
'SQL > 심화' 카테고리의 다른 글
| SQL튜닝 - Chpater07. SQL옵티마이저 (0) | 2023.08.26 |
|---|---|
| SQL튜닝 - Chapter05. 소트 튜닝 (0) | 2023.08.22 |
| SQL튜닝 -Chapter04.조인튜닝 -4- 서브퀴리 조인 (0) | 2023.08.22 |
| SQL튜닝 -Chapter04.조인튜닝 -3- 해시 조인 (1) | 2023.08.21 |
| SQL튜닝 - Chapter04.조인튜닝 -2- 소트 머지 조인 (0) | 2023.08.21 |


